Función SAP HANA K-MEANS para agrupar Big Data
Grupos para ventas e inventarios a través de meses y años
Author: Quantum Statistics
Email: qestadinfo@gmail.com
1) Introducción al algoritmo estadístico SAP HANA K-MEANS para encontrar la agrupación de datos de múltiples variables.
Los pasos para comprender K-MEANS y sus aplicaciones son muy complejos. Antes de entrar en detalles, recomiendo ver este video en youtube.
https://www.youtube.com/watch?v=utQHX1xyYAs&feature=youtu.be
Explica:
a) La complejidad de tratar de encontrar la segmentación de datos solo con un gráfico.
b) La aplicación del algoritmo K-MEANS
c) Ejemplo con creación de datos y tablas en SAP HANA.
d) Parámetros para definir el número de segmentación de grupo.
e) Tabla de resultados y CENTROIDES para explorar la segmentación.
f) Ejecutar la función K-MEANS como un ejemplo en vivo.
Representación del gráfico 3D para tres variables de datos: INGRESOS, GASTOS DE VIDA y GASTOS DE NOTICIAS. La necesidad es encontrar los números óptimos de grupos de este universo de datos para la estrategia de segmentación.
El código fuente y las consultas SQL para crear e INSERTAR valores en las tablas se publican en GITHUB: el primer ejemplo práctico con código y explicación en el Capítulo 3. Instrucciones generales con enlaces a pasos detallados para la instalación y configuración de la base de datos SAP HANA en las instalaciones está en el Capítulo 6.
|

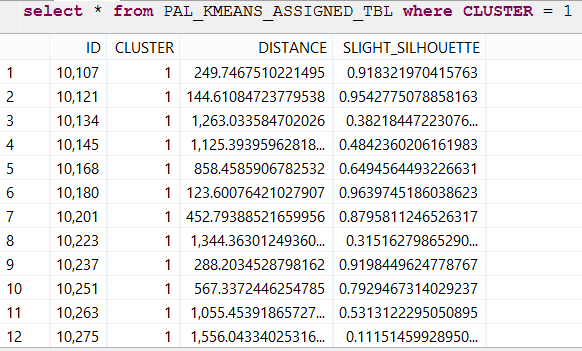
El indicador SILHOUETTE del valor de la función K-MEANS SAP HANA está entre -1 y 1. El número óptimo de GRUPOS de CLUSTERS tiene un valor cercano a 1. Esta es la primera información de la función K-MEANS para comprender el universo de datos . Una vez que se conoce el número de grupos, ejecute la función K-MEANS para encontrar los CENTROIDES. Después de varias interacciones, el algoritmo K-MEANS encuentra las posiciones óptimas de los CENTROIDES para cada segmentación de grupo. Con los CENTROIDES la segmentación de datos es clara.
Figura 1.2 Después de varias interacciones, los CENTROIDES (en círculos negros) alcanzan la posición final de los GRUPOS o agrupaciones. |
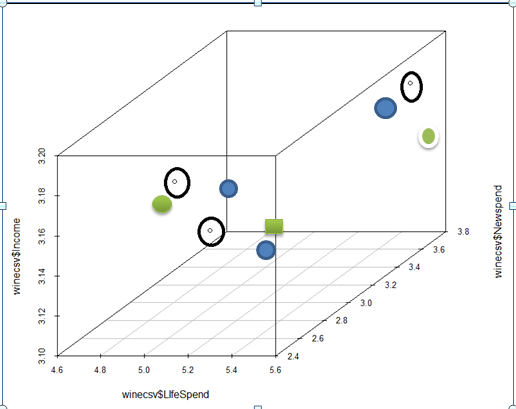
Cada ID de centroide se une a la tabla de datos para obtener las posiciones de las filas multivariables. Ver la figura 1.2 como ejemplo. Este ejemplo es para el CLUSTER número 0.
Figure 1.3 |

1.1) Estructura de la función SAP HANA K-MEANS
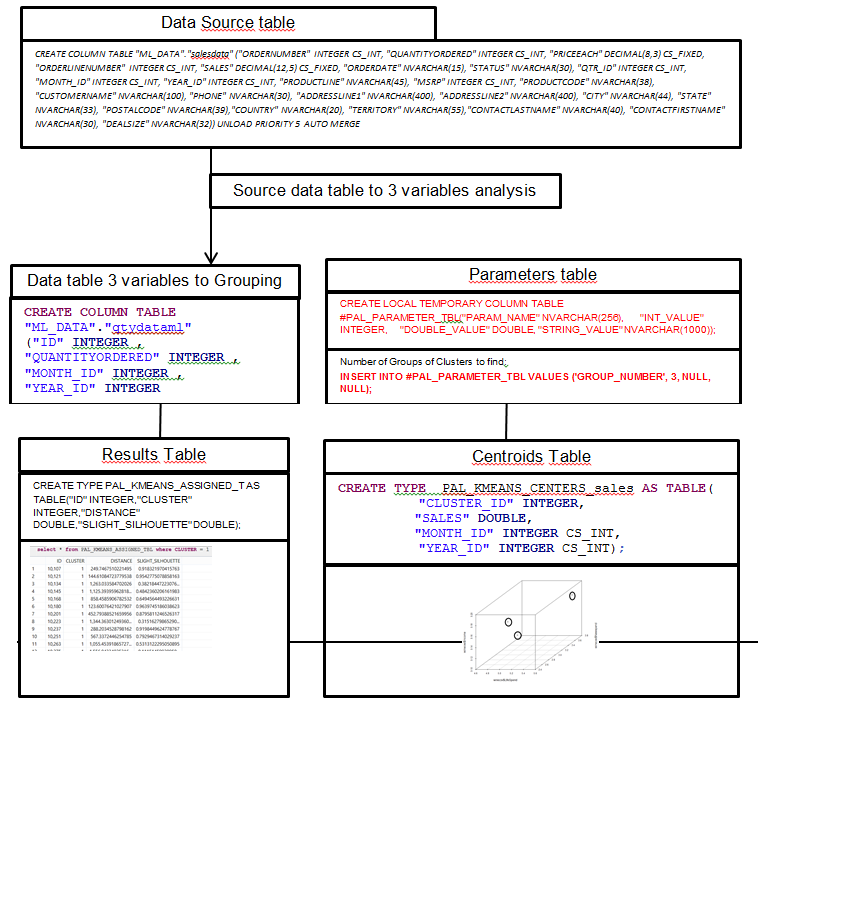
Results table:
Figure 1.4 |
La función K-Means SAP HANA toma como tabla de ENTRADA los datos de las 3 variables en SALESDATAML. El valor principal establecido en las tablas PARAMETERS es GRUP_NUMBER. Valor óptimo obtenido del indicador SILHOUETTE. Aplicar
select avg(SLIGHT_SILHOUETTE) from "ML_DATA".PAL_KMEANS_ASSIGNED_TBL
Después de varias ejecuciones para encontrar el mejor valor para el número de GRUPOS.
Los resultados se almacenan en la tabla PAL_KMEANS_ASSIGNED_TBL.
Los CENTROIDES o CENTROS de cada GRUPO se almacenan en PAL_KMEANS_CENTERS_sales.
Estos son los conceptos principales para trabajar con el algoritmo SAP HANA K-MEANS.
No comments:
Post a Comment